I took another detour into the world of binary neural networks. In the interests of evaluating dot-product-like functions of two binary vectors, I wanted to assess how the distributions of multiplied bits (equivalent to ANDed bits) relate to the distributions of the individual bits. This post captures the results of this side-trip.
Products of independent Bernoullis
The simplest case is in the light of independence, when $$X \sim Bern(\pi_{X})$$
$$Y \sim Bern(\pi_{Y})$$ and $$P(X,Y) = P(X)P(Y)$$
Let $Z = XY$ be the product of the two bits, equivalent to $Z=X \land Y$. As $Z \in \{0, 1\}$ we can model $Z \sim Bern(\pi_Z)$ for some $\pi_Z$.
The truth table for the four possible outcomes guides us here:
$X$
$Y$
$Z$
$P(X)$
$P(Y)$
0
0
0
$1-\pi_X$
$1-\pi_Y$
0
1
0
$1-\pi_X$
$\pi_Y$
1
0
0
$\pi_X$
$1-\pi_Y$
1
1
1
$\pi_X$
$\pi_Y$
$P(Z=1) = P(X=1)P(Y=1) = \pi_X \pi_Y$; a bit of arithmetic also shows that $P(Z=0) = 1 – \pi_X \pi_Y$. With $\pi_X \in [0,1] \land \pi_Y \in [0,1] \implies \pi_X \pi_Y \in [0, 1]$, we see that $$Z \sim Bern(\pi_X \pi_Y)$$
Products of Non-Independent Bernoullis
Suppose that $X \sim Bern(\pi_X)$. A second Bernoulli random variable will be dependent on $X$ only if its single parameter is a function of $X$, so let $Y|X \sim Bern(g(X))$ where $g : \{0, 1\} \to [0,1]$ generates the parameter of $Y$’s distribution.
As there are only two possible outcomes from such a function $g$ we denote them individually as: $$\pi_{Y|X=0} = g(0)$$ and $$\pi_{Y|X=1} = g(1)$$
We again are interested in the distribution of a given $Z = XY = X \land Y$, and again the truth table leads us to a straightforward solution:
$X$
$Y$
$Z$
$P(X)$
$P(Y|X)$
0
0
0
$1-\pi_X$
$1-\pi_{Y|X=0}$
0
1
0
$1-\pi_X$
$\pi_{Y|X=0}$
1
0
0
$\pi_X$
$1-\pi_{Y|X=1}$
1
1
1
$\pi_X$
$\pi_{Y|X=1}$
$$P(Z=1) = P(X=1) P(Y=1 | X =1) = \pi_{X} \pi_{Y | X = 1} = \pi_{X} g(1)$$
A bit of arithmetic shows that $$P(Z=0) = 1 – \pi_{X} \pi_{Y|X=1} = 1 – \pi_{X} g(1)$$
With $\pi_{X} \in [0,1] \land \pi_{Y|X=1} \in [0,1] \implies \pi_{X} \pi_{Y | X = 1} \in [0,1]$ we conclude that $$Z \sim Bern(\pi_{X} \pi_{Y | X = 1})$$
The parameter $\pi_{Y|X=0} = g(0)$ for the case where $X=0$ drops out; it is redundant as $Y=1 | X = 0$ is simply another way for $Z$ to equal zero.
In other words, the distribution of $Z$ depends only on the distributions of $X$ and of $Y | X = 1$, not on $Y | X = 0$. The constraint that all events must result in either one or the other of two outcomes allows the behavior of the combined system to be fully characterized with a constant number of parameters, and the distribution of the product / Boolean AND even of dependent Bernoullis is simply yet another Bernoulli.
As part of my effort to develop a probabilistic interpretation of transformer language models, I became interested in alternative position encodings to that used in Attention Is All You Need.
A position encoding can be characterized as some function from a non-negative integer to a vector of reals:
$$e : \mathbb{N} \to \mathbb{R}^{K}$$
or as a matrix carrying out the same function for a finite number of sequence positions, where the encoded vector can be used to reconstruct the sequence position, and where deltas between sequence positions can be captured by a linear map.
The point of the sequence encoding is to inform a language model of where in a sequence a word was located, rather than merely what the word was, and to allow the model to refer to token positions in both absolute and relative terms. Typically the encoding is summed with the token embedding. This can be viewed as a generalization of, rather than alternative to, concatenation.
Requirements
My requirements for a position encoding:
That the encoding be similarly invertible by an artificial neural network as is the sine/cosine encoding in common use.
That relative positions can be captured easily by a neural network mode, as described in subsection 3.5 in Attention Is All You Need. This means that we can train a linear map which can transform position encodings from one position to the correct position encoding of a relative position. This property seems to hold in general; we do not evaluate it empirically.
That the encoded vector play nicely with probabilistic token embeddings, i.e. have a well-understood statistical distribution. Even though position encodings will be deterministic, it would be helpful to be able to interpret them as just another random variable—one which happens to have all its mass on a single outcome.
A Normally Distributed Position Encoding
We might as well start with the best-understood distribution and try to generate normally distributed position encodings.
More specifically, we want to construct encoding vectors of dimension $K$ such that each element at index $k$ is distributed according to the univariate normal distribution $\mathcal{N}(\mu_k, \sigma_k)$. This is equivalent to a multivariate normal with no covariance between components (a special property of the multivariate normal; lack of covariance does not typically imply independence.)
To get encodings that are normally distributed according to these distributions (if non-random) we reformulate the problem in terms of the sequence position divided by a maximum length $N$, giving us encodings as functions of real-valued positions distributed evenly within $[0, 1]$:
$$e(i) = e'(i / N)$$
(This assumes a known maximum length, which is a disadvantage relative to the sine/cosine encoding.)
With inputs in $[0, 1]$ we now find a corresponding sample in each of the $K$ normals such that the same percentage of the distribution lies below it: in other words, we use the inverse CDF of the normal distribution, which is commonly available. Let
$$F^{-1}_k : [0, 1] \to \mathbb{R}$$
be the inverse CDF of $\mathcal{N}(\mu_k, \sigma_k)$. Then:
$$e'(x) = [F^{-1}_{1}(x), F^{-1}_{2}(x), …, F^{-1}_{K}(x)]$$ and
For evaluation purposes, we investigate the invertibility of the following encodings:
sincos: Attention Is All You Need-style sine/cosine encoding. Even components $2k$ are $sin(pos / 10000^{2k / K})$ and odd components $2k+1$ are $cos(pos / 10000^{2k / K})$.
direct1: the first dimension of the encoding equals $i/N$; the rest are zeros.
directN: all dimensions of the encoding equal $i/N$.
linear_normal: the encoding is the position as a decimal ($i/N$) multiplied by a vector of random reals plus a random bias, all initialized as samples from standard normal.
linear_normal_learned: like linear_normal, but the weights and bias are learned during training rather than static.
linear_uniform: like linear_normal, but with weights and bias initialized from a uniform distribution on $[-1, 1]$.
linear_uniform_learned: like linear_uniform, but the weights and bias are learned rather than static.
normal: the normally distributed encoding described above.
normal_learned: like normal, but the parameters of the normals are all learned.
Inversion
The invertibility of an encoding is measured by training a function
$$g : \mathbb{R}^{K} \to [0, 1]$$
that attempts to recover the original position divided by the sequence length, from the position encoding vector. For simplicity, we let $g$ be an affine transform with sigmoid activation function (in other words, a standard “dense” neural network layer):
where $\sigma$ is the standard logistic function. The loss is the mean squared error; the optimizer is Adam with a learning rate of $1^{-3}$.
Empirical Evaluation
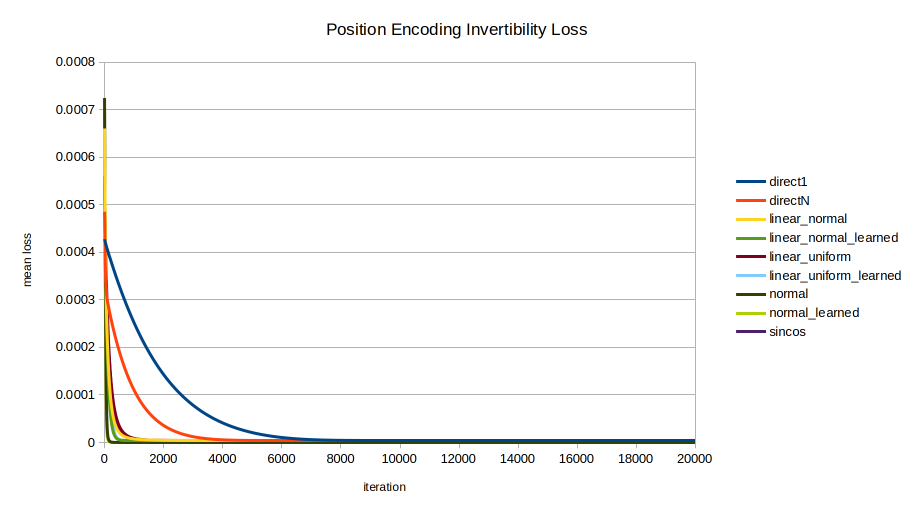
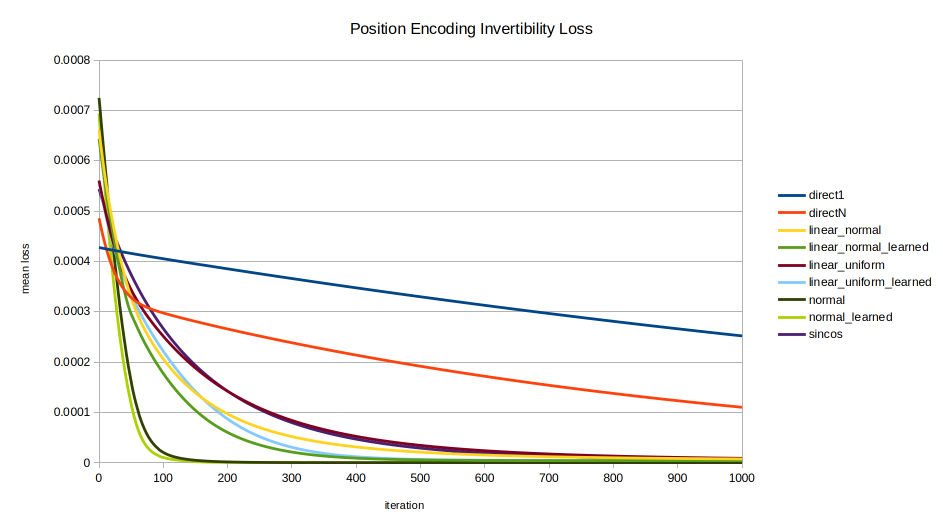
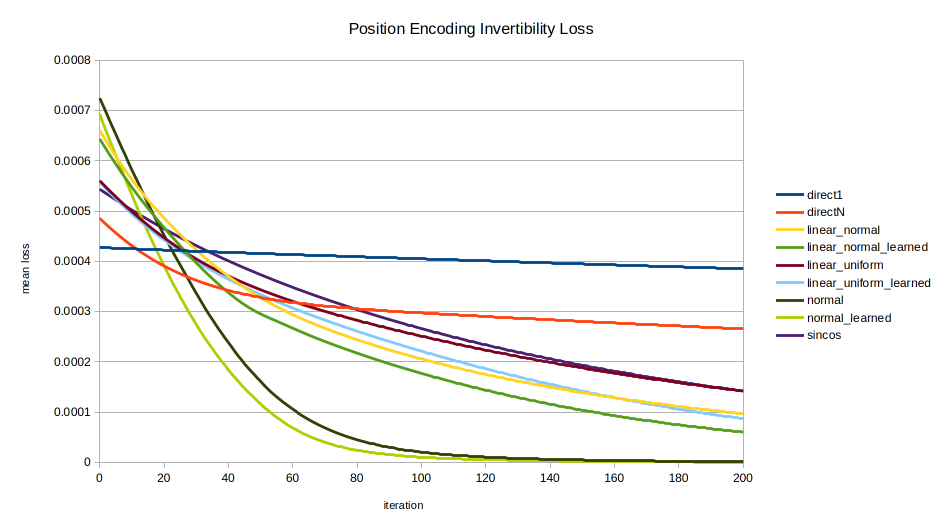
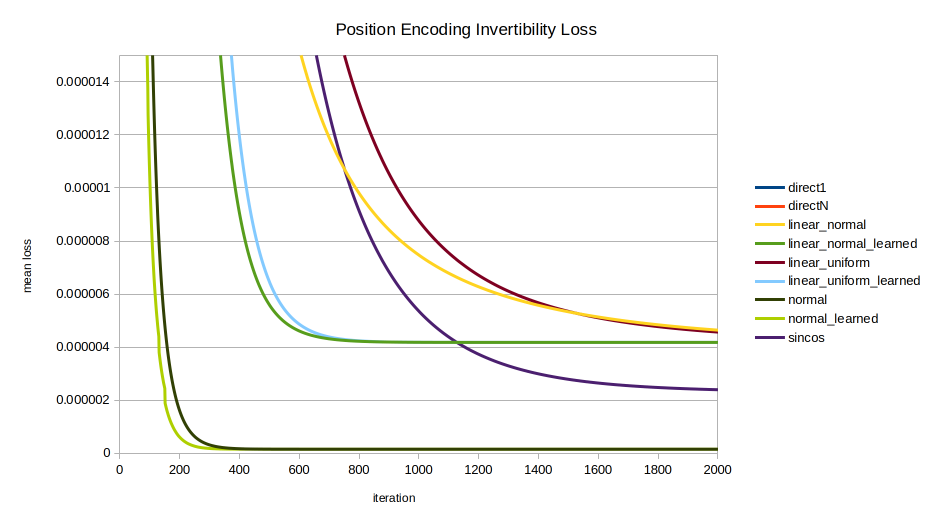
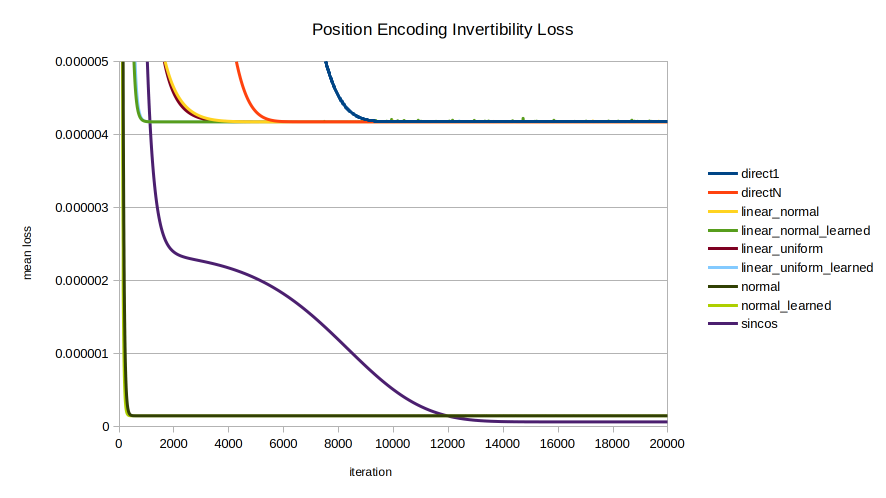
Each of the nine encodings was evaluated in terms of the speed with which the optimizer could recover the position from the position encoding. The mean across 100 random initializations is shown, trained for 20000 iterations. A few views are shown to highlight different trends; note the axes vary between images.
Overview. This view of the entire data series shows clearly that the direct encodings (red and blue) are curiously the worst of all. While directly encoding into all $K$ dimensions instead of just 1 makes inversion of the encoding easier, it still lags far behind other methods. This view also shows that at a certain resolution, over a long enough training time, there is no real distinction between methods.Overview 1k. The first 1000 iterations. In the shorter run, however, the different encodings display markedly different behavior in invertibility. normal and normal_learned are the clear standouts, unexpectedly as they were formulated for statistical intelligibility, not for invertibility.The “junction” where all encodings perform similarly, prior to diverging around 20-25 iterations.sincos advancement. The early performance of normal, normal_learned, linear_normal_learned, and linear_uniform_learned are seen, with sincos overtaking all but normal and normal_learned by about 1200 iterations.The money shot. Here we see all essential relationships between the encodings. All but normal, normal_learned, and sincos eventually converge on the same performance as the direct encodings. linear_normal_learned and linear_uniform_learned are interesting for achieving peak inversion performance sooner than sincos; but in the long run they also converge on the performance of direct1 and directN. Meanwhile the normally distributed encodings normal and normal_learned by far perform best in inversion performance until finally being overtaken by sincos late in the game around 12,000 iterations.
Implementation
The following should get the position encoding analysis running:
git clone https://github.com/joshhansen/MLPortfolio.git
# Optional: `git switch faf064b`
# to get the code version at time of publication.
cd MLPortfolio/pos-enc-invert
python -m venv ./venv
source ./venv/bin/activate
pip install -r packages.txt
python pos-enc-invert.py
It is surprising that the most direct procedures for position encoding (multiplying by a random vector; representing positions as values in $[0,1]$) are the worst performers, all converging upon essentially the same performance in the long run.
In all cases, allowing the encoding parameters to be learned leads to quicker convergence of the inverter model, but seemingly converges to the same inversion loss.
In all cases, normally distributed is inverted faster than uniformly distributed.
sincos as expected performs well in both inversion convergence speed and in long-run performance. It was originally selected with care.
Unexpectedly as they were chosen for reasons of well-characterized statistical distribution rather than ease of inversion, the normally distributed encodings normal and normal_learned converge far faster, to a far lower loss, than all other encodings considered, until being overtaken late by sincos. normal reaches a near-horizontal-asymptote by about 400 iterations; and normal_learned by about 300.
Conclusion
It remains unclear why a position encoding that yields normally distributed (if non-random) vectors is so easy for a neural network to invert—even more so than for the sine/cosine encoding in common use and formulated largely for its invertibility.
What’s more clear is that the method proposed here should have utility as a standalone position encoding, and may also serve as a useful part of a broader effort to develop probabilistic interpretations of transformer language models.
The paradigm is Bayesian epistemology. The broader task is to infer a rational worldview from empirical observation. Here, we use a collection of documents as our link to the real world: we observe that somebody created a document like this.
Roughly speaking, we infer our rational worldview by forcing Bayes’ rule in all possible combinations of model weights and observations. The engine of this arrangement is a language model conditioned on propositional knowledge paired with a knowledge model conditioned on language.
Preliminaries
In reality, there are at least two Bayes’ rules: the discrete and the continuous. We we use the continuous form:
where each function is a probability density function / conditional density.
To make a continuous distribution over something discrete like words, we use a traditional word embedding summed with positional encoding, then passed through the PDF of a multivariate normal distribution with inferred mean and covariance matrix. (How this interacts with the positional encoding I’m not clear on….)
$P(\vec{w})$—a general language model. This decomposes by the chain rule as $P(\vec{w}) = \Pi_{i} P(w_i | \vec{w}_{j < i})$.
Implementation: unclear; we need a probabilistic language model; can we get a probabilistic interpretation of a transformer?
$P(K)$—a general knowledge model. How likely, a priori, is a belief or statement to be true?
Implementation: a multivariate normal would be a starting point
$P(\vec{w} | K)$—the knowledge-conditional language model. This is the probability of a document $\vec{w}$ given some assertion of the state of the world, the nature of reality, or whatever, $K$. $K$ may make claims about a subset of reality; the world is a complex place, so it’s helpful to be able to discuss parts of it rather than always the whole. This is enabled by the marginalizability of the multivariate normal as discussed above. Of course by the chain rule this decomposes to $\Pi_{i} P(w_i | \vec{w}_{j < i})$.
Implementation: uncertain; a multivariate normal parameterized by a transformer with $K$ as input?
$P(K | \vec{w})$—the language-conditional knowledge model. Given a word and its context, how likely is an assertion about our model to be true?
Implementation: uncertain; another probabilistic transformer? A multivariate normal whose parameters are a function of $\vec{w}$, perhaps the output of a transformer?
$P(K|J)$ where $K$ and $J$ are disjoint propositions—a hypotheticals model. What does assuming part of our model say about the rest of our model?
Implementation: multivariate normal parameterized by output of a transformer
Training Procedure
Randomly sample word-with-context $\vec{w}$ and knowledge vector $\vec{k}$. Randomly partition $\vec{k}$ into disjoint vectors $\vec{q}$ and $\vec{r}$. Compute the gradient of the loss:
The first part critically evaluates the interrelationship of model components. The second part critically evaluates the explanatory power of the model relative to empirical observation.
Language models, at the core, are very stupid, blindly predicting the next word given the preceding words. This leaves them profoundly vulnerable to the biases and inaccuracies of the training data.
Human annotations are applied late in the game to reduce spurious, hallucinatory, extremist, discriminatory, and other undesired outputs, but this after-the-model reshaping is symptomatic of the fact that there is no critical thinking in the language model proper. It can’t assess the reasonableness of the text it’s generating; only the likelihood that the words would be spoken. Of course, some things are so widely accepted that they go without saying; and others, like propaganda, are repeated precisely because of their untruth.
This task is to distill from biased textual inputs a rational world-model, so far as it is implicit in the training data.
What makes a model rational?
A “rational” model does its best to be both internally consistent and to comport with empirical observations. If this consistency respects Bayes’ rule, it embodies Bayesian epistemology; we here term such a model Bayes rational.
The first requirement of Bayes rationality, internal consistency, can be seen as adherence to Bayes’ rule between all pairs of model parameters:
But having internal consistency is not enough to render a worldview rational. Theory must also relate to observation in a manner consistent with Bayes’ rule. Observation consistency applies Bayes’ rule to every model parameter-observation pair:
A large dataset of lossless images from Wikimedia Commons, with 25%, 50%, and 128×128 downscales, plus train and validation splits for an image super-resolution task.